Data Analytics with Python
Exploring a range of Python tools used for data analytics, categorized by their applications.
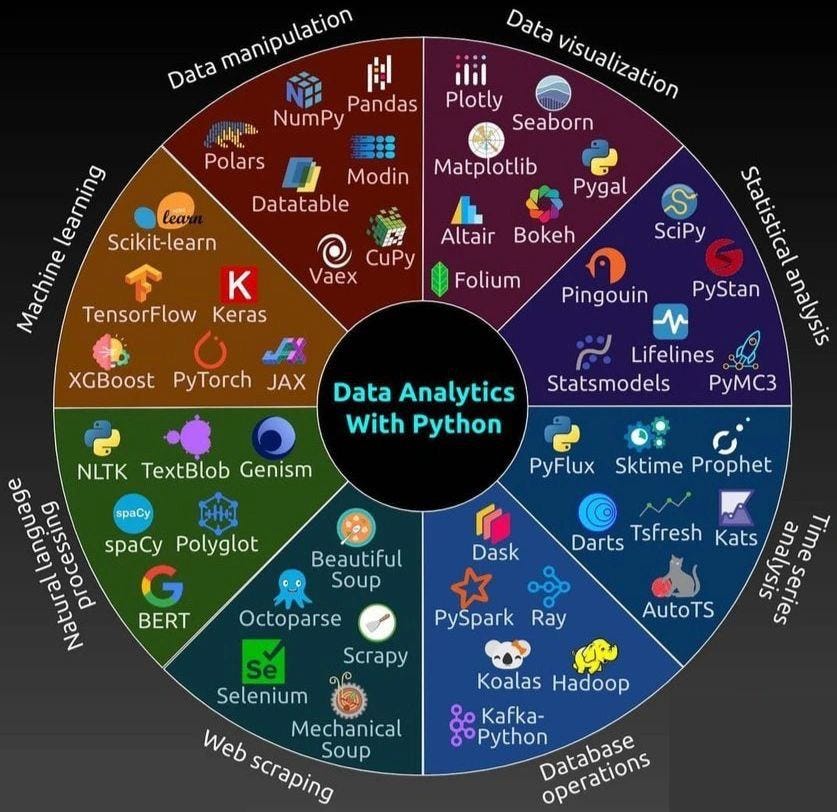 |
| Data Analytics with Python |
Machine Learning
1. Scikit-learn: A versatile library providing simple and efficient tools for data mining and data analysis. It includes algorithms for classification (e.g., decision trees, k-NN), regression (e.g., linear regression, SVR), clustering (e.g., k-means, DBSCAN), and more. It also offers tools for data preprocessing, feature selection, and model evaluation.
2. TensorFlow: TensorFlow is an open-source machine learning framework developed by Google. It supports both deep learning and traditional machine learning tasks. TensorFlow is highly scalable, supports GPU acceleration, and is widely used for training large deep-learning models. TensorFlow 2.x integrates Keras for ease of use and improved performance.
3. Keras: Keras is a high-level API for building and training deep learning models, which works as an interface to TensorFlow. It simplifies the process of building neural networks by providing pre-built layers, optimizers, and loss functions. Keras is known for its simplicity and user-friendliness.
4. XGBoost: A popular implementation of gradient boosting, which is an ensemble technique used for regression, classification, and ranking tasks. XGBoost is highly efficient, handling large datasets and complex models with high performance. It supports distributed computing and is frequently used in data science competitions.
5. PyTorch: PyTorch is an open-source machine learning library, especially popular in academia. It provides dynamic computation graphs (which allows for flexible model development) and is known for its user-friendly interface. PyTorch is also highly optimized for GPU computing and supports deep learning tasks such as vision and NLP.
6. JAX: JAX is a numerical computing library developed by Google that offers automatic differentiation and GPU/TPU support. It provides a high-performance alternative to NumPy with features like just-in-time (JIT) compilation for faster execution and automatic differentiation for gradient-based optimization.
Natural Language Processing
1. NLTK: The Natural Language Toolkit (NLTK) is a leading platform for building Python programs that work with human language data. It offers easy-to-use interfaces to over 50 corpora and lexical resources, along with a wide range of text-processing libraries for tasks such as tokenization, stemming, tagging, and parsing.
2. TextBlob: TextBlob is a simpler NLP library that provides tools for common text processing tasks such as part-of-speech tagging, noun phrase extraction, sentiment analysis, and classification. It is built on top of NLTK and Pattern, providing a high-level API for working with text data.
3. Gensim: Gensim is an open-source library used for topic modeling, document similarity analysis, and natural language processing. It excels at handling large text corpora and offers models like Latent Dirichlet Allocation (LDA) and Word2Vec for word embeddings.
4. spaCy: spaCy is a fast and efficient library for advanced NLP tasks. It supports tokenization, part-of-speech tagging, named entity recognition, dependency parsing, and word vectors. spaCy is designed for production use and is highly optimized for performance.
5. PolyGlot: PolyGlot is a multi-purpose NLP pipeline supporting over 200 languages. It provides pre-trained models for tasks such as language detection, translation, and text classification, making it useful for global-scale NLP applications.
6. BERT: BERT (Bidirectional Encoder Representations from Transformers) is a state-of-the-art NLP model developed by Google. BERT uses a transformer architecture to understand the context of words in relation to all the other words in a sentence. It has revolutionized NLP by providing pre-trained models that can be fine-tuned for various tasks like question answering, sentence classification, and entity recognition.
Web Scraping
1. Octoparse: Octoparse is a no-code, visual web scraping tool that allows users to scrape data from websites without programming knowledge. It features a point-and-click interface, along with powerful features like automatic pagination handling and data export options.
2. Selenium: Selenium is an automation tool primarily used for web application testing, but it also works well for scraping dynamic websites. It simulates browser interactions, allowing you to scrape content rendered by JavaScript, which static tools like Beautiful Soup may not capture.
3. MechanicalSoup: MechanicalSoup is a Python library that automates interaction with websites using the requests and BeautifulSoup libraries. It’s useful for scraping simple websites and automating tasks such as form submission and login.
4. Scrapy: Scrapy is a fast, open-source web crawling and scraping framework for Python. It’s ideal for scraping large websites and processing vast amounts of data. Scrapy handles data extraction, cleaning, and exporting to various formats (CSV, JSON, etc.).
5. Beautiful Soup: Beautiful Soup is a Python library that helps you parse HTML and XML documents and extract data from them. It provides methods to search and navigate the parse tree, making it easy to extract content like text, links, and tables.
Data Manipulation
1. Polaris: Polaris is a Python tool that allows interactive data exploration with visualizations. It helps users quickly analyze large datasets by providing simple ways to explore data distributions and relationships.
2. NumPy: NumPy is a foundational package for scientific computing in Python, providing support for large, multi-dimensional arrays and matrices. It includes a powerful set of mathematical functions to manipulate these arrays and perform complex computations.
3. Pandas: Pandas is a widely-used library for data analysis and manipulation. It provides high-performance, easy-to-use data structures like DataFrame and Series. Pandas simplifies data cleaning, reshaping, merging, and aggregation tasks, making it essential for data preprocessing.
4. Modin: Modin is an optimization of Pandas, designed to scale processing across multiple cores or distributed environments. It allows you to run your existing Pandas code with minimal modifications but faster performance on large datasets.
5. Dask: Dask is a parallel computing library that extends the capabilities of NumPy, Pandas, and Scikit-learn. It is designed for working with large datasets that do not fit into memory by breaking them into smaller chunks and processing them in parallel.
6. Datatable: Datatable is a data manipulation library optimized for large datasets. It provides functionality similar to Pandas, but with performance improvements for out-of-core computations and parallel processing.
7. Vaex:Vaex is designed for efficient manipulation of large datasets by loading data lazily and performing computations in a memory-efficient manner. It is particularly useful for large tabular datasets that don’t fit into memory.
8. CuPy: CuPy is a library that enables NumPy-like array operations on NVIDIA GPUs, providing fast computation for large datasets, particularly useful in scientific computing and deep learning.
Data Visualization
1. Plotly: Plotly is an interactive graphing library that allows you to create web-ready plots. It supports various chart types, including line, bar, scatter, 3D plots, and geographical maps. Plotly is widely used for creating dashboards and publishing interactive reports.
2. Matplotlib: Matplotlib is a 2D plotting library for Python that enables you to create static, animated, and interactive visualizations. It is highly customizable and works well for simple plots like histograms, bar charts, and scatter plots.
3. Seaborn: Seaborn builds on top of Matplotlib and provides a higher-level interface for creating statistical visualizations. It includes several built-in themes and color palettes to make plots more aesthetically pleasing and informative.
4. Pygal: Pygal is a Python library for creating SVG (Scalable Vector Graphics) charts. It’s ideal for creating interactive and high-quality charts with a small footprint and easy-to-read syntax.
5. Altair: Altair is a declarative statistical visualization library, meaning you specify what data you want to visualize and how, while Altair handles the rest. It uses a grammar of graphics and integrates well with the Vega-Lite framework.
6. Bokeh: Bokeh is an interactive data visualization library that enables the creation of web-based visualizations. It’s suited for dashboards, streaming data, and complex plots with interactive elements like sliders, hover tools, and zooming.
7. Folium: Folium is a Python library for creating interactive maps using the Leaflet.js library. It is commonly used for visualizing geospatial data and plotting data points on maps, such as displaying the locations of events or geographical trends.
Statistical Analysis
1. SciPy: SciPy is built on top of NumPy and provides additional functionality for scientific and technical computing. It includes modules for optimization, integration, interpolation, eigenvalue problems, and more.
2. Pingouin: Pingouin is a lightweight library for statistical analysis, designed for simplicity and ease of use. It supports a variety of statistical tests, correlation coefficients, ANOVA, and more.
3. Statsmodels: Statsmodels is a library for statistical modeling that includes classes for linear and non-linear regression, time series analysis, hypothesis testing, and more. It’s particularly useful for econometrics and statistical research.
4. PyStan: PyStan is a Python interface to Stan, a powerful probabilistic programming language for statistical modeling. It allows you to create Bayesian models and fit them using Markov Chain Monte Carlo (MCMC) sampling.
5. PyMC3: PyMC3 is a library for probabilistic programming that enables users to build Bayesian models using MCMC or variational inference. It supports complex statistical modeling and is often used in data analysis and decision-making problems.
Time Series Analysis
1. PyFlux: PyFlux is a library for time series modeling and forecasting. It supports various models like ARIMA, GARCH, and others for both univariate and multivariate time series.
2. Sktime: Sktime is a library specifically for time series machine learning. It provides tools for classification, regression, and forecasting tasks, and supports model evaluation and hyperparameter tuning.
3. Prophet: Prophet is a forecasting tool developed by Facebook. It is particularly effective for forecasting data with strong seasonal patterns, and it includes features like automatic holiday effects.
4. Darts: Darts is a time series forecasting library that simplifies working with time series data and integrates machine learning models for forecasting tasks. It supports probabilistic forecasting and model evaluation.
5. TsFresh: TsFresh is a Python library for automatic extraction of relevant features from time series. It can help in feature engineering, which is a critical part of building time series prediction models.
6. AutoTS: AutoTS is an automated time series forecasting library. It simplifies the process of building forecasting models by automatically selecting the best model and tuning its parameters.
7. Kats: Kats is a toolkit developed by Facebook for time series analysis, including anomaly detection, forecasting, and seasonal decomposition. It is designed for ease of use and quick prototyping.
Database Operations
1. Koalas: Koalas is a library that brings the familiar Pandas API to Apache Spark. It allows users to perform data science operations on big data, seamlessly scaling from small datasets to large ones without needing to learn Spark’s syntax.
2. Kafka-Python: Kafka-Python is a Python client for Apache Kafka, a distributed streaming platform used for real-time data pipelines. It allows you to interact with Kafka for data streaming and message handling.
3. Hadoop: Hadoop is a widely used open-source framework for processing and storing large datasets in a distributed computing environment. It uses the MapReduce model for parallel data processing and HDFS (Hadoop Distributed File System) for data storage.
These tools cover a wide variety of applications in data science, machine learning, and data engineering, providing the functionality needed for everything from simple data manipulation to complex machine learning tasks. The specific choice of tool will depend on your project’s requirements, scale, and performance needs.




No comments:
Post a Comment