The Machine Learning Pipeline
A Step-by-Step Guide to Building and Deploying Models
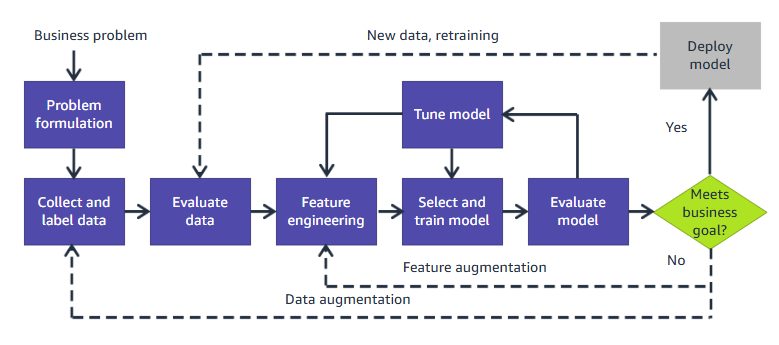 |
| ML Pipeline |
Machine learning (ML) has become an essential tool for solving complex business problems, enabling organizations to extract meaningful insights from data. The ML pipeline provides a structured approach to achieve this goal. In this article, we’ll break down each step in the ML pipeline to help you understand its components and practical implementation.
1. Problem Formulation: Defining the Goal
The journey
begins with problem formulation, where the business problem is clearly
defined. This step involves collaboration between business stakeholders and
data scientists to answer questions such as:
- What is the
problem we are trying to solve?
- What metrics
will define success?
- How will the
solution impact business objectives?
For example, a
business might want to predict customer churn, improve product recommendations,
or optimize inventory management. This step transforms vague objectives into
concrete, machine-learning-specific tasks like classification, regression, or
clustering.
2. Collect and Label Data: Building the
Foundation
Data is the
backbone of machine learning. In this phase, you collect data from various
sources such as databases, APIs, IoT devices, or web scraping. Key
considerations include:
- Data Volume:
Ensure sufficient data for model training.
- Data
Quality: Address issues like missing values or inconsistent formats.
- Data
Relevance: Use data directly tied to the problem.
For supervised learning tasks, labeling data is critical. For example, if building a model to classify emails as spam or not, emails must be tagged as “spam” or “not spam” during this phase.
3. Evaluate Data: Assessing Data Quality
Once data is collected, it undergoes thorough evaluation.
This step focuses on:
- Identifying
missing values, duplicates, or anomalies.
- Analyzing
data distribution to detect biases or imbalances.
- Visualizing
the data to uncover patterns or relationships.
Tools like
Pandas, NumPy, and visualization libraries such as Matplotlib or Seaborn are
often used for this purpose. If gaps are detected, corrective measures like
data cleaning or augmentation are applied.
4. Feature Engineering: Preparing Data for
Modeling
Raw data often
needs transformation to unlock its potential. Feature engineering is the
art of creating meaningful features from the data, which includes:
- Feature
Scaling:
Normalize or standardize features to ensure equal treatment in models.
- Feature
Selection:
Remove irrelevant or redundant features to improve model efficiency.
- Data
Augmentation:
Generate synthetic data to enhance diversity (e.g., flipping or rotating
images in computer vision).
For example, in a dataset of customer purchases, you might create a new feature like "average monthly spending" to help the model detect spending patterns.
5. Select and Train the Model: Building
Intelligence
This step
involves choosing an appropriate ML algorithm based on the problem type and
dataset size. Common algorithms include:
- Linear
Regression
for predicting continuous values.
- Decision
Trees
and Random Forests for classification tasks.
- Neural
Networks
for complex tasks like image or speech recognition.
The training process involves feeding the data into the selected model and optimizing it to minimize error. Modern ML frameworks like TensorFlow, PyTorch, and Scikit-learn make this step streamlined and efficient.
6. Evaluate the Model: Testing Performance
The trained model
must be rigorously tested to ensure it performs well on unseen data. Key steps
in model evaluation include:
- Splitting
data into training, validation, and test sets.
- Measuring
performance using metrics such as accuracy, precision, recall, F1-score,
or RMSE (Root Mean Square Error).
- Identifying
areas where the model underperforms, such as specific data segments.
If the model’s performance is inadequate, this feedback loop informs the need for further adjustments.
7. Tune the Model: Enhancing Accuracy
Model tuning
involves fine-tuning hyperparameters to optimize performance. Techniques
include:
- Grid Search or Random
Search: Explore different combinations of hyperparameters.
- Cross-Validation: Test model
stability across multiple data subsets.
- Regularization: Prevent
overfitting by penalizing overly complex models.
This phase is
iterative, with adjustments made until the model achieves satisfactory results.
8. Meets Business Goals? Assessing Success
Once the model is
evaluated and tuned, it’s time to validate its success against business goals.
This step asks:
- Does the
model provide actionable insights?
- Are the
predictions accurate and reliable for real-world application?
- Is the model
aligned with the business’s key performance indicators (KPIs)?
If the answer is No,
the pipeline loops back to earlier stages, such as data collection, feature
engineering, or model selection, to refine the process.
9. Deploy the Model: Making It Operational
When the model
meets business objectives, it’s ready for deployment. Deployment involves:
- Integrating
the model into a production environment (e.g., APIs, cloud platforms).
- Setting up
monitoring systems to track performance and detect drift.
- Automating
retraining with new data to keep the model relevant.
Popular tools
like AWS SageMaker, Google AI Platform, and Azure ML facilitate smooth
deployment and monitoring.
Continuous Iteration: The Never-Ending Cycle
Machine learning
is a dynamic process. As business needs evolve and new data becomes available,
the ML pipeline must adapt. Regular retraining, model updates, and performance
reviews ensure the solution remains effective over time.
The ML pipeline
provides a systematic approach to solving business problems using machine
learning. By following these nine steps—problem formulation, data collection,
data evaluation, feature engineering, model training, evaluation, tuning,
deployment, and iteration—you can build robust, scalable models that deliver
tangible business value.




No comments:
Post a Comment