An Overview of Machine Learning Algorithms
A Must-Know for Data Scientists
 |
| Machine Learning Algorithms |
Machine Learning (ML) is a branch of artificial intelligence (AI) that focuses on building systems capable of learning and improving from experience. For data scientists, understanding the wide array of machine learning algorithms is crucial for applying the right solutions to data-driven problems.
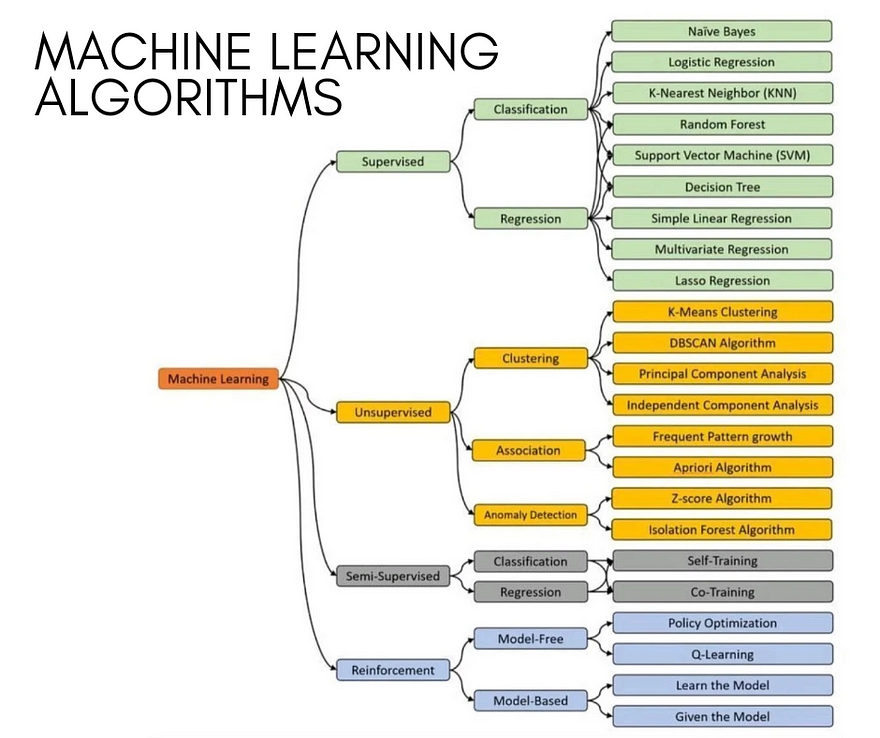
Algorithms can be categorized into Supervised Learning, Unsupervised Learning, Semi-Supervised Learning, and Reinforcement Learning. Let’s dive into the key details of each category and their respective algorithms.
1. Supervised Learning
Supervised learning algorithms learn from labeled datasets, meaning each data point is paired with the correct output. The main tasks include Classification and Regression.
Classification
Classification algorithms are used to predict categorical outputs (e.g., spam vs. not spam). Key algorithms include:
1. Naive Bayes: Based on Bayes' theorem, this algorithm assumes feature independence. It's commonly used in text classification.
2. Logistic Regression: A statistical method for binary classification problems.
3. K-Nearest Neighbor (KNN): Classifies a data point based on its proximity to other labeled data points.
4. Random Forest: A decision tree-based ensemble method that improves accuracy by averaging results from multiple trees.
5. Support Vector Machine (SVM): Finds the hyperplane that best separates data into classes.
6. Decision Tree: A tree-like model for making decisions, splitting data based on feature importance.
Regression
Regression models predict continuous outputs (e.g., house prices). Algorithms include:
1. Simple Linear Regression: Finds a linear relationship between two variables.
2. Multivariate Regression: Handles multiple independent variables.
3. Lasso Regression: Adds regularization to minimize overfitting.
2. Unsupervised Learning
Unlike supervised learning, unsupervised learning deals with unlabeled data, discovering hidden patterns or structures. It is primarily used for Clustering, Association, and Anomaly Detection.
Clustering
Clustering groups data points based on similarity. Popular algorithms include:
1. K-Means Clustering: Partitions data into k clusters by minimizing the distance between points and their cluster centroid.
2. DBSCAN (Density-Based Spatial Clustering of Applications with Noise): Groups points based on density and identifies outliers.
3. Principal Component Analysis (PCA): Reduces data dimensionality by identifying key features.
4. Independent Component Analysis (ICA): Similar to PCA but focuses on statistical independence between components.
Association
Association algorithms discover relationships between variables in large datasets:
1. Frequent Pattern Growth: A method to mine frequent itemsets efficiently.
2. Apriori Algorithm: Commonly used in market basket analysis to identify rules like "If a customer buys X, they are likely to buy Y."
Anomaly Detection
These algorithms detect unusual patterns or outliers:
1. Z-Score Algorithm: Identifies anomalies by measuring the standard deviations away from the mean.
2. Isolation Forest: An ensemble-based method to isolate anomalies effectively.
Semi-Supervised Learning
Semi-supervised learning uses a mix of labeled and unlabeled data, making it useful for scenarios where labeling data is expensive or time-consuming.
Classification
Self-Training: Initially trains a model with labeled data, then uses predictions on unlabeled data to retrain.
Regression
Co-Training: Trains multiple models on different views of the same data to improve performance.
Reinforcement Learning
Reinforcement learning focuses on training agents to make decisions by interacting with an environment, aiming to maximize cumulative rewards. It is categorized into Model-Free and Model-Based approaches.
Model-Free
1. Policy Optimization: Improves decision-making policies directly.
2. Q-Learning: Learns the value of actions to maximize future rewards.
Model-Based
1. Learn the Model: Develop a model of the environment for planning.
2. Given the Model: Uses a pre-defined model for decision-making.
How to Choose the Right Algorithm?
The choice of an algorithm depends on:
1. Data type: Labeled or unlabeled data.
2. Goal: Classification, regression, clustering, or anomaly detection.
3. Complexity: Some algorithms, like Random Forest, are more computationally intensive.
4. Interpretability: Simple models like Logistic Regression are easier to explain compared to Neural Networks.
Machine learning offers a diverse toolkit for solving complex problems. Understanding these algorithms' strengths, weaknesses, and applications is essential for data scientists to build robust and efficient models.
Mastering this hierarchy of algorithms equips you to handle various challenges, from predicting customer behavior to uncovering hidden insights in data.




No comments:
Post a Comment